Reihenfolge von Features im FME Prozess steuern
Grundsätzlich arbeitet ein FME Prozess die zu verarbeitenden Features sequenziell ab. Ein eingelesenes Objekt durchläuft dabei zunächst einmal alle Transformer und wird dann mithilfe des Writers ins gewünschte Zielformat geschrieben. Danach wird das nächste Feature verarbeitet und so weiter.
Dieses Prinzip gilt allerdings nicht für FME Prozesse, die sogenannte gruppenbasierte Transformer enthalten. Diese Art von Transformern kann mehrere Objekte gleichzeitig verarbeiten, was zu einer Änderung der Objektreihenfolge führen kann.
Um mehrere Features gemeinsam zu prozessieren, speichern gruppenbasierte Transformer die eingehenden Daten zwischen. Erst wenn alle Objekte, die gemeinsam verarbeitet werden, am Transformer angekommen sind, erfolgt die Bearbeitung.
Durch ein Steuern in welcher Reihenfolge Features an gruppenbasierten Transformern ankommen, kann die Menge der zwischenzuspeichernden Daten reduziert und so die Performance des Workspaces optimiert werden.
Ein Einfluss auf die Reihenfolge der Features ist auch in anderen Anwendungsfällen hilfreich. So steuern Sie beispielsweise auch in welcher Reihenfolge Daten in ihr Zielformat geschrieben werden.
FME bietet unterschiedliche Möglichkeiten, Features zu sortieren und zu steuern in welcher Reihenfolge Prozessabschnitte ausgeführt werden. Einige dieser Möglichkeiten stellen wir in diesem Artikel vor.
Reihenfolge steuern, in der Daten eingelesen werden:
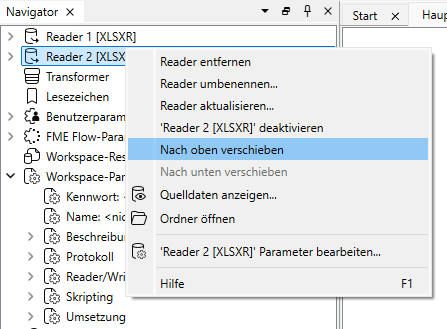
Wenn Ihr FME Workspace mehrere Reader enthält, können Sie steuern, welcher der Reader zuerst ausgeführt wird. Ein Anpassen der Reader-Reihenfolge ist über den Navigator möglich. Der dort an oberster Stelle aufgeführte Reader wird immer zuerst ausgeführt.
Um die Reader-Reihenfolge zu verändern, machen Sie im Navigator einen Rechtsklick auf den Reader, den Sie verschieben möchten, und wählen Sie „Nach oben verschieben“ bzw. „Nach unten verschieben“ („Move Up“ bzw. „Move Down“) aus.
Reihenfolge steuern, in der Creator Transformer ausgeführt werden:
Einige Workspaces enthalten keine Reader und werden mithilfe von Creator Transformern gestartet.
Sollten mehrere Creator in einem Workspace enthalten sein, kann auch hier gezielt festgelegt werden, in welcher Reihenfolge die Creator Transformer und somit die jeweiligen Prozessabschnitte ausgeführt werden.
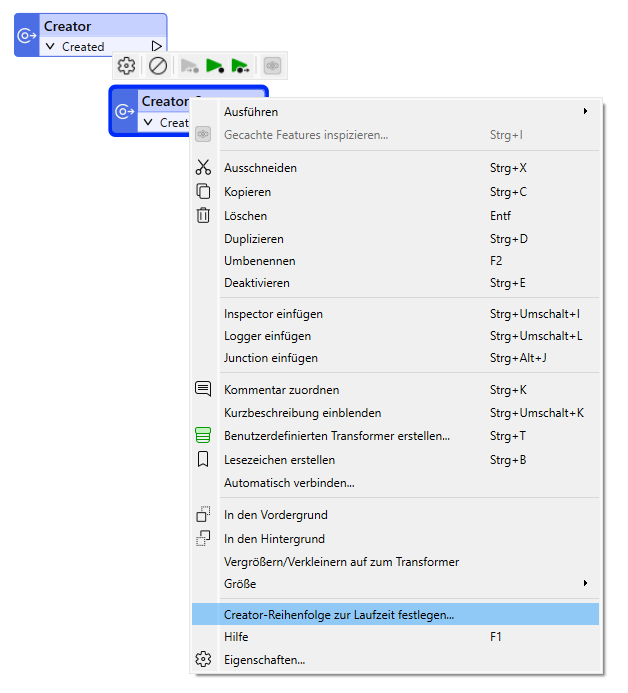
Um die Ausführungsreihenfolge zu definieren, machen Sie einen Rechtsklick auf einen der Creator und wählen Sie „Creator-Reihenfolge zur Laufzeit festlegen…“ („Set Creator Runtime Order“).
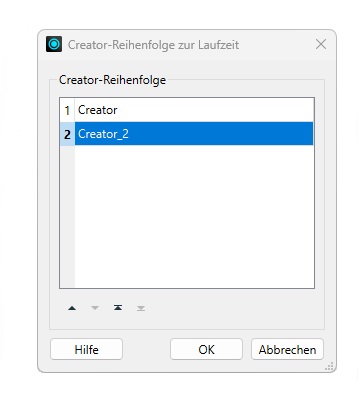
Im sich öffnenden Dialogfenster kann die Creator-Reihenfolge nun mithilfe der Pfeilsymbole angepasst werden.
Tipp: Sollten im Workspace SQLCreator oder PythonCreator Transformer enthalten sein, können Sie auch die Reihenfolge, in der diese Transformer ausgeführt werden, über den zuvor beschriebenen Weg steuern.
Reihenfolge steuern, in der ein Transformer Daten an unterschiedliche Verbindungen sendet:
Der Output-Port eines Transformers oder eines Reader Feature Types kann mehrere Verbindungen haben. Features, die an diesen Port gesendet werden, können so auf unterschiedliche Arten weiterverarbeitet werden.
Auch hier können Sie steuern, wohin die Daten zuerst übermittelt werden.
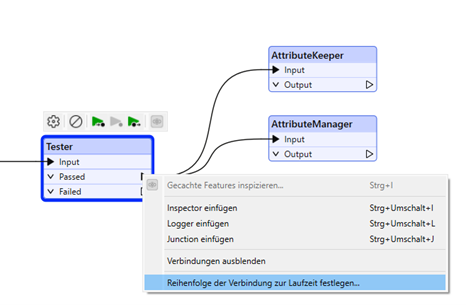
Machen Sie dafür einen Rechtsklick auf den Output-Port oder auf eine der Verbindungen und wählen Sie „Reihenfolge der Verbindung zur Laufzeit festlegen“ („Set Connection Runtime Order“). Im sich nun öffnenden Dialogfenster können Sie bestimmen, welche Verbindung zuerst bedient wird.
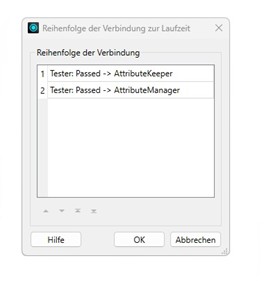
Reihenfolge über den Transformer Sorter anpassen:
Über die vorgestellten Methoden hinaus, kann der Transformer Sorter genutzt werden, um die Feature-Reihenfolge anzupassen. Der Transformer erlaubt sowohl ein alphabetisches wie auch ein numerisches Sortieren. Eine Ausgabe der Daten ist entweder aufsteigend oder auch absteigend möglich.
Im Transformer definieren, in welcher Reihenfolge Features dort ankommen:
Mithilfe der genannten Schritte können Sie Ihre Daten in die gewünschte Reihenfolge bringen.
Um die optimierte Feature-Reihenfolge nun zu nutzen, um weniger Daten zwischenzuspeichern, ist noch eine Anpassung an den jeweiligen gruppenbasierten Transformern notwendig.
Wurden die Features beispielsweise nach Gruppenzugehörigkeit sortiert, kann im gruppenbasierten Transformer die Einstellung „Complete Groups“ auf „Wenn sich die Gruppe ändert (Erweitert)“ („When Group Changes (Advanced)“) gestellt werden. Sobald eine Gruppe vollständig ist, werden die Features nun direkt verarbeitet. Die Menge der zwischengespeicherten Daten wird somit reduziert.

Bei einigen Transformern mit mehreren Input-Ports wie dem Clipper oder dem PointOnAreaOverlayer können Sie nach einem ähnlichen Prinzip festlegen, in welchen der Ports zuerst Daten eingehen.
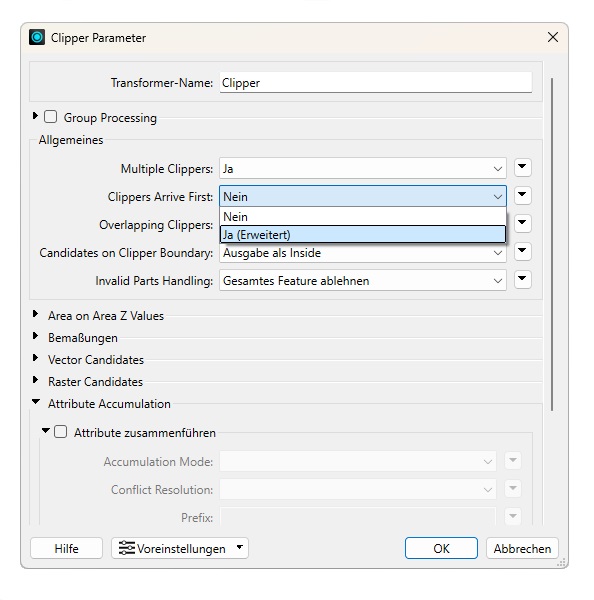
Hinweis: Diese Transformer-Parameter sollten nur dann angepasst werden, wenn über den Workspace sichergestellt ist, dass die Daten den Transformer in der angegebenen Reihenfolge erreichen. Entspricht die Feature-Reihenfolge nicht der Einstellung im Transformer können ggf. falsche Ergebnisse entstehen.
Hinweis: In unserer Videoserie FME zum Kaffee sehen Sie auch wie das Ganze funktioniert. Das Video und weitere Folgen finden Sie in unserem YouTube Kanal:
https://www.youtube.com/user/conterrachannel
Schauen Sie doch mal vorbei!

